IEEE SLT 2026 · interactive demo
ARIA
An analytic source–filter neural vocoder with an
interpretable, decoupled control surface, built for phonetic research.
ARIA exposes the parameters phoneticians already reason with
(F0, F1, F2, phonation and prominence, plus an exploratory nasalisation control) as controls
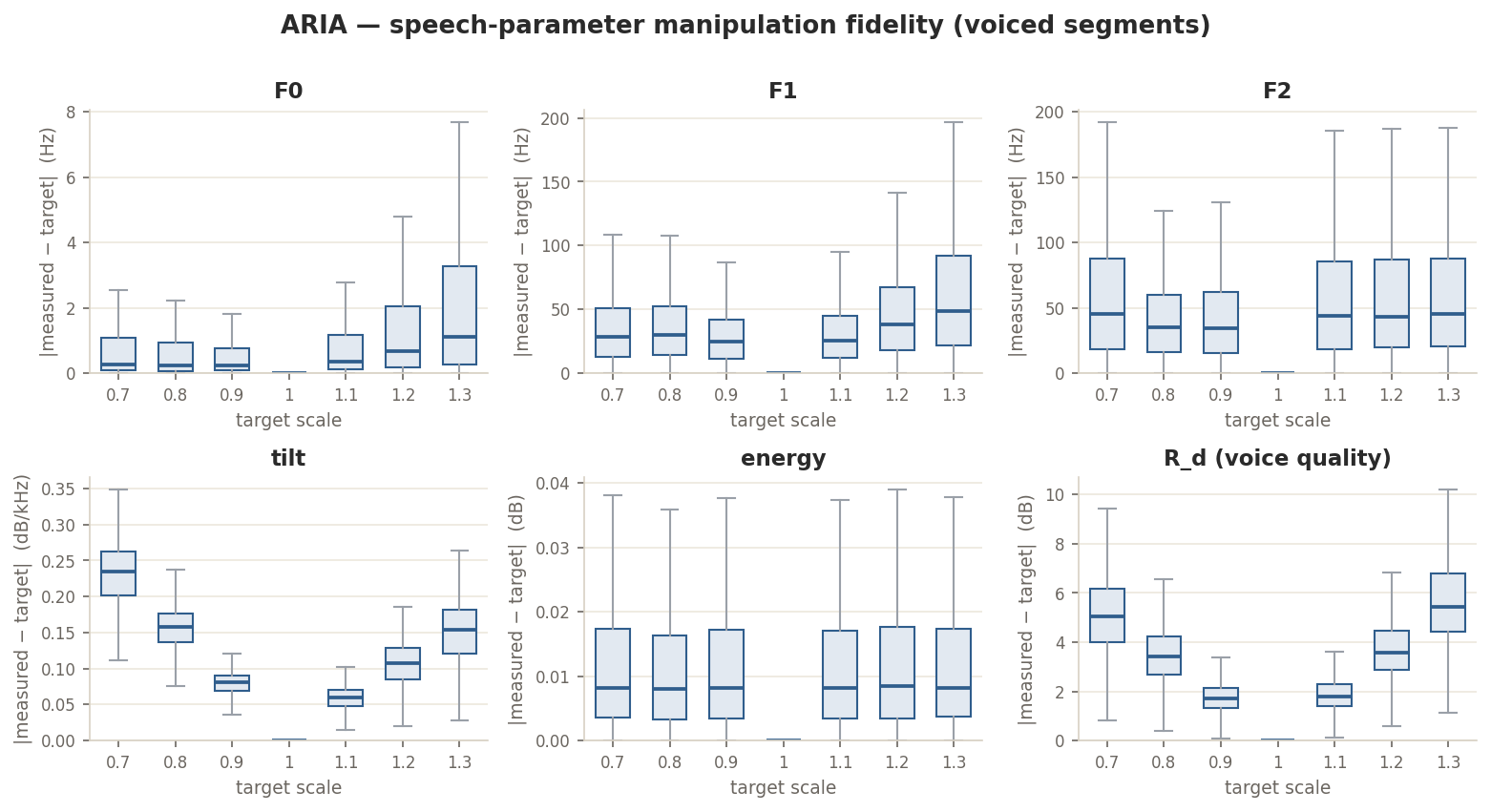
over a neural vocoder. The network estimates them; deterministic DSP places each
pole/source parameter directly. Move the pitch or vowel control and the others hold: F0, F1
and F2 are cleanly independent (the source and prominence controls overlap by design).
- 6
- independent phonetic dimensions (7 studio controls)
- ≈ 40 Hz
- median F2 manipulation error
- from 1 h
- single-speaker audio per voice